
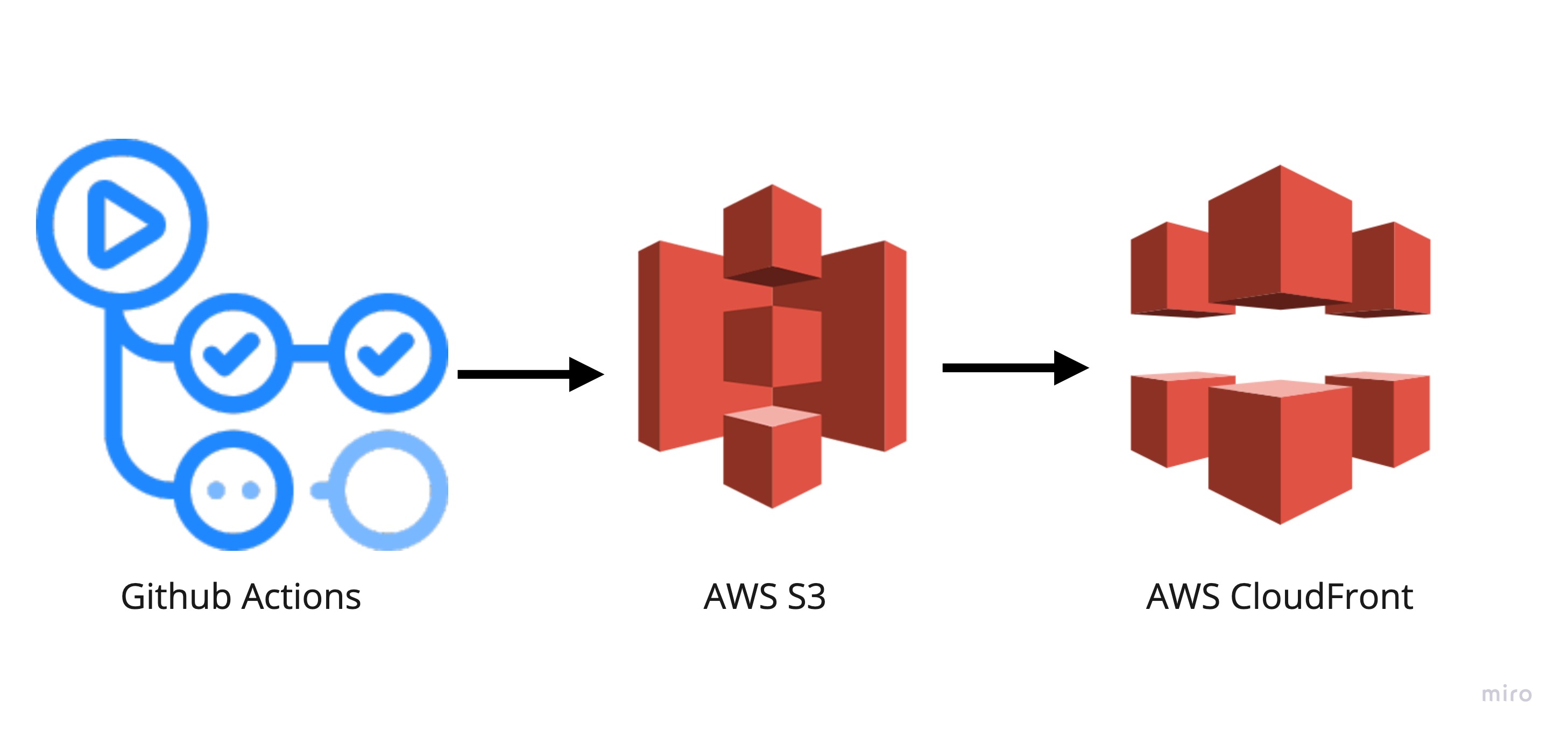
A key part of implementing micro frontends is to achieve independent deployments of the individual apps.
We have implemented a micro frontend architecture using Webpack Module Federation. Our system is organised in a mono-repo and we use GitHub Actions for our CI/CD pipeline. We have a separate GitHub Workflow for each module, and the workflows only execute when a change in the appropriate directory has occurred. Changes in multiple directories trigger workflows to run in parallel
The workflows perform all necessary tasks as defined, build the modules and push the built files to an S3 bucket. In front of our S3 bucket we have configured a CloudFront distribution to deliver the entry for our system and enable client side routing.
If you are interested in how we have implemented a micro frontend architecture with Webpack Module Federation you can read all about it in this article.
Hosting architecture
We store all of our build artifacts in a common AWS S3 bucket. The folders with built files for each module are located in the same relative paths in S3 as the source for each module in our repository, ie. the folders inside packages.

|

|
| Repo structure | S3 structure |
In front of our S3 bucket we have a CloudFront distribution which is configured to serve the index.html file from the main remote module. When users try to access our application they hit CloudFront, which responds with the corresponding file from the S3 bucket.

Origin is set to our S3 bucket. It is important that it is set to the root of our bucket and not a subdirectory eg. /main , for our relative paths to work.
 The root object is index.html from the main remote module
The root object is index.html from the main remote module
Once the index.html file is received by the client, the application renders and remote modules (the micro frontends) are loaded from S3 via CloudFront when needed.

Requesting https://my-app.com/subscriptions/some-file.js from the client will hit CloudFront. Since the origin in CloudFront is our bucket CloudFront will fetch https://my-bucket/subscriptions/some-file.js and deliver it to the client.
Client routing with CloudFront
Our application is a Single Page Application (SPA), meaning it has a single entry point (index.html file) and routing is handled on the client. Hitting the application at the root, https://my-app.com. and navigating from there works just fine. However, trying to directly enter the application or refreshing the page on a route other than the root, for example at https://my-app.com/some-path, would normally result in a 404 error. CloudFront cannot find a matching file to respond with. You may also run into a 403 error if CloudFront understands the request but won't provide the response, for example if the file is not publicly accessible. Either way, since we have a SPA, we always want to serve the same index.html file when a user tries to access our applications. Routing and errors should be handled by our application on the client.
To enable this we create custom error responses in our CloudFront distribution. We define error responses so that 404 and 403 errors in CloudFront respond with status code 200 and the entry point for our single page application, to the client.

A request for something that is not an actual accessible file in S3 will receive index.html from the main remote module in the response from CloudFront. Client side routing is now enabled and any invalid paths are handled internally by our application.
Deployment process
Further, we have three environments for our application, development , staging and production .
We have a stable master branch with tested production code.
- Merge to
masterautomatically deploys the applications that have changed to production. - We also support manually deploying any application on the master branch to production with a GitHub workflow dispatch.
We have a somewhat stable stage branch that should always be runnable.
- Merge to
stageautomatically deploys the applications that have changed to staging. - Opening or updating a pull request on the stage branch automatically deploys the incoming feature branch to development. Since we have independent deployments having multiple open PRs with changes on different modules will deploy the different modules to the development environment without them effecting each other or anything else. If there are multiple PRs open with changes on the same module the latest deploy will override that module in the development environment, leaving everything else untouched.
- We support manually deploying any application on the stage branch to staging with a GitHub workflow dispatch.
We work with feature branches from the stage branch
- We support manually deploying any application on any brach to development with a GitHub workflow dispatch.
- Pushing to a feature branch with an open pull request automatically deploys the feature branch to development. Described in more details above.
We have a pretty progressive CI/CD pipeline and a lot of movement in development of new features in the frontend and the backend, with many daily merges into stage. To give ourselves some slack and avoid having to synchronise deployment with the backend services, we decided to have a stage branch in front of our master branch. We prefer having separate branches for the different environments, rather than deploying the same branch to different environments. Our staging environment is always up to date with our stage branch, and our production environment is always up to date with our master branch. Our development environment is a playground without rules for ad-hoc testing.
Okey, that sounds nice (hopefully), but how have you implemented it?
GitHub actions
As mentioned, each of our micro frontends has its own workflow. Let's take a look at the workflow for the subscriptions app. Notice the paths array. This is what enables the workflow to run only when there have been changes in a specific directory.
The trigger for the workflow for our subscriptions app, that supports the strategy described above looks like this.
name: Deploy subscriptions
on:
push:
branches: [stage, master]
paths: ['packages/subscriptions/**']
pull_request:
branches: [stage]
types: [opened, synchronize]
paths: ['packages/subscriptions/**']
workflow_dispatch:We then create steps to set environment variables based on the branch we are deploying to make sure we use the correct AWS environment. As the build files for all of the micro frontends are stored in the same S3 bucket, we need to specify the correct folder in the bucket.
jobs:
deploy-main:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- uses: actions/setup-node@v1
with:
node-version: 12
- name: Set dev credentials
if: github.ref != 'refs/heads/stage' && github.ref != 'refs/heads/master'
run: |
# configure environment variables with credentials
# to be uses by the aws cli in a later step here
echo "AWS_ACCESS_KEY_ID=${{ secrets.DEV_AWS_ACCESS_KEY_ID }}" >> $GITHUB_ENV
echo "AWS_SECRET_ACCESS_KEY=${{ secrets.DEV_AWS_SECRET_ACCESS_KEY }}" >> $GITHUB_ENV
echo "CF_DISTRIBUTION=${{secrets.DEV_CF_DISTRIBUTION}}" >> $GITHUB_ENV
echo "BUCKET=s3://my-dev-bucket/subscriptions" >> $GITHUB_ENV
- name: Set stage credentials
if: github.ref == 'refs/heads/stage'
run: |
...
- name: Set production credentials
if: github.ref == 'refs/heads/master'
run: |
...Other actions we need are install and build. You can add as many steps as you need in your workflow. We chose to add a step that caches our node modules. This lets us skip installation of packages and reuse the node modules cached from previous workflow runs whenever our lock-file is unchanged.
- name: Cache node modules
uses: actions/cache@v2
id: cache
env:
cache-name: cache-node-modules
with:
path: ~/.npm
key: ${{ hashFiles('./packages/subscriptions/package-lock.json') }}
- name: Install dependencies
if: steps.cache.outputs.cache-hit != 'true'
run: |
cd packages/subscriptions/
npm ci
- name: Build subscriptions app
run: |
cd packages/subscriptions/
npm run buildUpload the build to our S3 bucket. Se note on caching below.
- name: Upload to S3
run: |
aws configure set aws_access_key_id "$AWS_ACCESS_KEY_ID"
aws configure set aws_secret_access_key "$AWS_SECRET_ACCESS_KEY"
aws configure set default.region "$REGION"
cd packages/subscriptions/
aws s3 sync --cache-control 'max-age=604800' --exclude index.html --exclude remoteEntry.js ./dist/ "$BUCKET"
aws s3 sync --cache-control 'no-cache' ./dist/ "$BUCKET"Last, we added a step for invalidating CloudFront. This is to ensure that our users get the latest version of our app when reloading the page.
- name: Invalidate Cloudfront
run: |
aws configure set aws_access_key_id "$AWS_ACCESS_KEY_ID"
aws configure set aws_secret_access_key "$AWS_SECRET_ACCESS_KEY"
aws configure set default.region "$REGION"
aws cloudfront create-invalidation --distribution-id "$CF_DISTRIBUTION" --paths "/subscriptions/*"Note on versioning and caching
We extend the name of our built files with a unique hash to avoid overriding old files , and keep those old files in S3 to support active sessions on older versions of our app. However, we don't cache index.html or the entry files for the different micro frontends. This is to ensure that our users always get the latest version of our app when reloading the page. Whenever we deploy a new version of an app we also invalidate the CloudFront cache. See workflow above for more details.
Conclusion
There is some overhead in maintaining multiple workflows and a bit of duplicate code, which is something we are looking into improving. However, independent deployments give us a lot of freedom and are relatively easy to set up in a mono repo using GitHub Actions. You can deploy you changes faster while impacting a smaller scope of the system.